This website uses cookies. By clicking Accept, you consent to the use of cookies. Click Here to learn more about how we use cookies.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Head's Up! These forums are read-only. All users and content have migrated. Please join us at community.neo4j.com.
- Neo4j
- Technical Discussions
- Neo4j Graph Platform
- What is the difference between a CORE FOLLOWER and...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Printer Friendly Page
What is the difference between a CORE FOLLOWER and a READ_REPLICA if both are Read-Only?
10-14-2021 02:02 AM
Hi all,
I ran into the following on a CORE-only cluster: "No write operations are allowed directly on this database. Writes must pass through the leader. The role of this server is: FOLLOWER".
I access the node via HTTP, not Bolt (Because we started the project in PHP, when there was no Bolt connecort yet
The word FOLLOWER is self-explanatory, but in the cluster picture, it is also stated that CORE are meant for Read and Write
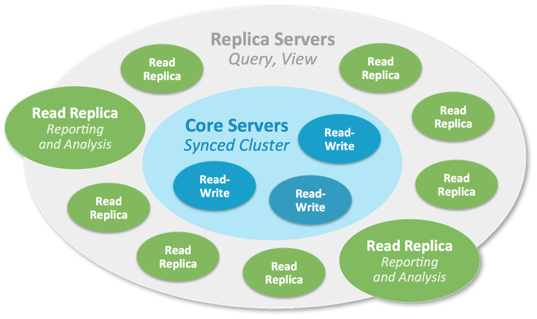{kind=link}
So, the question is: Why may not I write on that CORE which is meant for Read-Write?
Optionally: How can I make a multi-LEADER CORE cluster?
Labels:
- Labels:
-
Cluster
7 REPLIES 7
10-14-2021 02:47 AM
These terms are from the underlying raft consensus algorithm. A follower receives updates from the leader. A leader decides to commit a transaction based on the number of followers that confirmed that they have received an update.
A follower is also a candidate to become a leader when a leader election is triggered.
A read replica receives updates, but does not count towards consensus. It also will never become a leader. Read replicas are a bit like the database equivalent of a content-delivery network.
The reason you can't write to a follower is that there is no internal forwarding to the leader. The bolt drivers handle routing on the client-side by receiving routing information and relying on explicit read or write session types to decide where to send a given query.
-ABK
10-14-2021 03:54 AM
Thank you @abk ,
If I understand correctly, despite I set a 100 nodes CORE cluster up , only one is LEADER, so that this only one can receive writes?
But if I set a 100 nodes CORE cluster up, it is to be able to share (round robin or random, whatever) things amoung all (or most) nodes!
I mean, it missis the "cluster" side of the definition.
10-14-2021 02:57 AM
Looking into the current status of neo4j-php-client it looks like it should support routing when using neo4j:// connections.
Can you give that a try?
-ABK
10-14-2021 03:55 AM
@abk , too much refactoring before MVP launch would be required if we switch now.
10-14-2021 04:55 AM
A correction, it is possible to request server-side routing as explained in the Internals of clustering - Operations Manual .
Theoretically server-side routing would also forward http requests. I'm double checking on this as our documentation does not indicate whether or not it is possible. Will update this thread with whatever I learn.
Regarding clusters: the primary purpose of the cluster is resilience to failure. For reading, you can easily scale up read capacity by adding more members. However write operations are always serialized transactions. The data consistency guarantees would require multiple writers to coordinate their writes, returning to a serialized operation. Multiple writers are only possible with isolated data. A graph, by definition, is connected.
The way to crack that is to allow multiple graphs, which can then be independently updated. The problem is then what to do about querying across the independent graphs. That is the problem space of Neo4j Fabric.
Does that make sense?
Best,
ABK
10-14-2021 04:56 AM
For reference...
10-14-2021 06:19 AM
Regarding server-side routing of HTTP, that is not yet possible but is on the roadmap.
Best,
ABK
Nodes 2022
NODES 2022, Neo4j Online Education Summit
All the sessions of the conference are now available online
