This website uses cookies. By clicking Accept, you consent to the use of cookies. Click Here to learn more about how we use cookies.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Head's Up! These forums are read-only. All users and content have migrated. Please join us at community.neo4j.com.
- Neo4j
- Technical Discussions
- Neo4j Graph Platform
- Re: "Appendix" sub-graph detection
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Printer Friendly Page
10-03-2022 03:52 AM
Hey Neo4j!
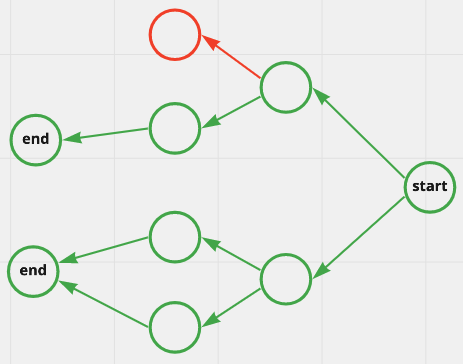
I'm looking for a way from a given "start" node to find all sub graphs which does not lead to a particular type of "end" node. I've attached a diagram of the kind of picture I want to produce, the "appendix" is marked in red, the rest in green.
GDS allShortestPaths at first seemed applicable, but
1) will not find longer-than-the-shortest-but-valid paths,
2) does not return the nodes and relationships along the way which I want to .write.
Can you hint at what would be the approach I should take with this, pls? Am I overlooking this algorithm (in GDS or APOC), or do I need to write my own custom algo for this?
Thanks a ton in advance!
Nis
Bonus question (for extra credit!):
Ideally I would want this not just as boolean values, but multiply a factor from the edges and store on nodes as the traversal progresses from start to end.
Solved! Go to Solution.
{kind=link}
1 ACCEPTED SOLUTION
10-03-2022 06:06 AM
Look at apoc path methods:
https://neo4j.com/labs/apoc/4.1/overview/apoc.path/
you should be able to achieve this in cypher, but it may not be efficient for a large graph. Something like this:
match(s:Label{id:0})
match p=(s)-[*]->(e)
where not exists ( (e)—>() )
and not e:Appendix
with nodes(p) as n, relationships(p) as rels
unwind n as node
with collect ( distinct n) as nodes, rels
unwind rels as rel
return nodes, collect (distinct rel) as relationships
Your extra credit answer would be to write your own custom procedure to traverse and update nodes in any manor you need.
Reply
6 REPLIES 6
10-03-2022 06:06 AM
Look at apoc path methods:
https://neo4j.com/labs/apoc/4.1/overview/apoc.path/
you should be able to achieve this in cypher, but it may not be efficient for a large graph. Something like this:
match(s:Label{id:0})
match p=(s)-[*]->(e)
where not exists ( (e)—>() )
and not e:Appendix
with nodes(p) as n, relationships(p) as rels
unwind n as node
with collect ( distinct n) as nodes, rels
unwind rels as rel
return nodes, collect (distinct rel) as relationships
Your extra credit answer would be to write your own custom procedure to traverse and update nodes in any manor you need.
Reply
10-06-2022 08:15 AM
match p=(s)-[*]-(e) does the trick. Indeed, it won't scale, but that's fine, I have other ways of running it just on subgraphs.
Also, good to know that there isn't a traversal algo I am overlooking.
Cheers!
10-06-2022 08:40 AM
Glad the worked. Writing a custom procedure is not difficult if you are java developer. The biggest hurdle is just getting a working unit test working for a shell procedure. Once that is done, writing the logic is not difficult. the code is compiled to a jar, which is then deployed to the server. The procedure is then available in your cypher queries. I can provide you with an example if this is something you are interested in.
10-06-2022 01:53 PM
I'd actually appreciate an example to get me started on that! I do know Java, and the idea of calling procedures from cypher is very appealing! Thanks!
Reply
10-10-2022 05:55 AM
I will put something together.
10-10-2022 12:55 AM
https://medium.com/@nis.jespersen/the-united-nations-trust-graph-d65af7b0b678
^ Here's the result of what I was building
On Medium, anyone can share insightful perspectives, useful knowledge, and life wisdom with the world.
Reply
Nodes 2022
NODES 2022, Neo4j Online Education Summit
All the sessions of the conference are now available online
Related Content
- Unable to import neo4j-p2p-data.dump into AuraDB (Neo4j v5) in Neo4j Graph Platform
- Getting Error in Louvain community detection algorithm in Neo4j Graph Platform
- Best visualization tool to analyze evolving communities? in Integrations
- Not detecting repeated nodes in Neo4j Graph Platform
- How to create a hierarchy of subgraphs/clusters? in Neo4j Graph Platform
