This website uses cookies. By clicking Accept, you consent to the use of cookies. Click Here to learn more about how we use cookies.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Head's Up! These forums are read-only. All users and content have migrated. Please join us at community.neo4j.com.
- Neo4j
- Technical Discussions
- Neo4j Graph Platform
- Lineage and skipping nodes
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Printer Friendly Page
Lineage and skipping nodes
11-21-2022 11:24 AM
Any help gratefully accepted re the following challenge.
I have a historic database of printers/print shops in the city of Antwerp (Belgium). Often these print shops were handed over from father to son, thus creating dynasties of upto 16 generations.
Let's say that they all have the same name (which was often the case anyway): John I, John II upto John XVI.
I am using #NeoDash to make all the data on these printers available, based upon a search of the name.
The first complication is that I need to indicated the source (a book, website, etc.) of every bit of data. So I cannot simply have the relationship (John I)<-[SUCCEEDED]-(John II) because I need to indicate where the SUCCEEDED-information came from. I therefore need to insert a "dummy node" which I then complement with a source:
(John I)<-[SUCCEEDED]-(u:DummyNode)-[SUCCEEDED_2]-(John II)
(u:DummyNode)-[FOUND_IN]->(Source)
One of the reports depicts the immediate predecessor and successor (without the sources because they are depicted in another report which is a table):
MATCH (n:Name)<-[r:HAS_NAME_VARIANT]-(p)
WHERE n.Name = $neodash_name_name
OPTIONAL MATCH (p)-[:SUCCEEDED]-(u)-[:SUCCEEDED_2]->(p3)-[:HAS_NAME_VARIANT {qualification: "preferred"}]->(n3)
OPTIONAL MATCH (p)-[:SUCCEEDED_2]-(u2)<-[:SUCCEEDED]-(p2)-[:HAS_NAME_VARIANT {qualification: "preferred"}]->(n2)
RETURN n, n2, n3, CASE WHEN exists((p2)--(n2)) THEN apoc.create.vRelationship(n, 'Succeeded', {}, n2) ELSE NULL END, CASE WHEN exists((p3)--(n3)) THEN apoc.create.vRelationship(n, 'Preceeded', {}, n3) ELSE NULL END(where $neodash_name_name is the parameter to look up a specific person and the distinction between (n) and (p) has to do with the fact that the name of a person can have a (large) number of spelling variants)
The query above works fine for the immediate predecessor and successor, see attachment.
So far, so good.
But here is the second challenge: what if I want to depict the complete lineage, including the predecessor of the predecessor, the successor of the successor, etc. ?
I could create two optional matches for resp. (p3) and (p2) to check if that person had a(nother) predecessor/successor. But since lineage can be upto 16 people and the query has to work for John I as well as for John XVI and any John in between, I would need 15 sets of 2 optional matches in either direction, resulting in... 62 optional matches..
And what if there turns out to be a lineage of 17, 18, 20,... people?
Somehow I think there must be a more elegant solution...
Thanks for any suggestions!
4 REPLIES 4
11-21-2022 01:45 PM
Here is my thoughts on this:
I created a sample data:
merge (a:Name {name:"John I"})
merge (a1:Name {name:"John II"})
merge (a2:Name {name:"John III"})
merge (a3:Name {name:"John IV"})
merge (a4:Name {name:"John V"})
merge (a4)-[:SUCCEDS {source:"Book"}]->(a3)
merge (a3)-[:SUCCEDS {source:"Book"}]->(a2)
merge (a2)-[:SUCCEDS {source:"Web"}]->(a1)
merge (a1)-[:SUCCEDS {source:"Book"}]->(a)
return a, a1, a2, a3, a4
Result:
Ran this query:
MATCH (a:Name) where a.name = "John I"
CALL apoc.path.spanningTree(a,{maxLevel:16}) YIELD path
return path
You can change the maxLevel number.
Result:

{kind=link}
Reply
11-22-2022 12:57 AM
Hi @ameyasoft , thanks for your input.
One of the problems is that I cannot include the source as a property of the relationship, see my reply to @glilienfield below.
And inasfar as I understand apoc.spanningTree, it cannot skip the dummy nodes. Hence the challenge...
11-21-2022 01:54 PM
The problem is make more complicated with the introduction of the Source nodes. Can you put the source information as a property of the SUCCEED relationship? If you want to node to reference, how about a model where you related the source between the two person nodes and let the SUCCEED relationship also be directly between the two person nodes? This would simplify your traversal to find the predecessors and successors.
What do you have SUCCEED and SUCCEED_2 relationships? Doesn't this also complicate the traversal?
Is the purpose of the virtual relationships so you can show a graph relating person name to person name; thereby, removing the complication of the intermediate relationships from the users?
Are all successor and predecessor relationships one-to-one?
This problem may be better solved with the help of one of the apoc path methods to direct all the different length paths.
Reply
11-22-2022 12:50 AM
@glilienfield : thanks for your thoughts.
There is indeed a long list of reasons why the source should be a node and not a property. The most important one is that it is a 1/n relationship: 1 bit of data can have (and mostly has) several sources. I cannot attach the [FOUND_IN] relationship to the (p)-node for sa similar reason.
Remains the dummy node as the only solution.
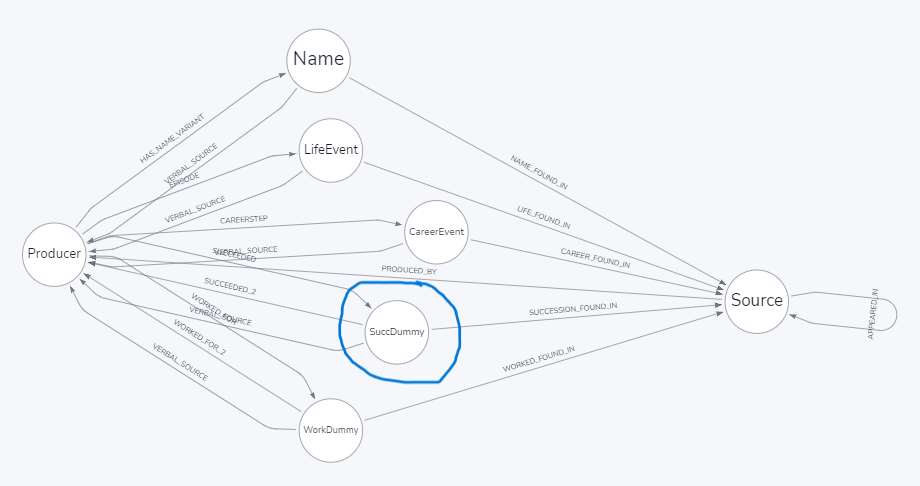
Attached is my schema (work in progress, about 10 nodes attached to (p:Producer) still need to be added).
Once I have established a relationship [SUCCEEDED] between (p) and the dummy, I can create a relationship with the Source-node. But then I still need to link to the successor/predecessor (who is also a (p) and that is what [SUCCEEDED_2] does.
Hope this clarifies.
{kind=link}
Nodes 2022
NODES 2022, Neo4j Online Education Summit
All the sessions of the conference are now available online
Related Content
- Skip nodes in a path in Neo4j Graph Platform
- performance issues with simple match on small graph (lineage analysis, cypher doesn't terminate) in Neo4j Graph Platform
- performance issues with simple match on small graph (lineage analysis, cypher doesn't terminate) in Neo4j Graph Platform
- Embeddings only for selected nodes. in Neo4j Graph Platform
